Xử lý ngôn ngữ tự nhiên, một nhánh điều tra và nghiên cứu của trí tuệ nhân tạo, được tăng trưởng nhằm mục đích thiết kế xây dựng những chương trình máy tính có năng lực nghiên cứu và phân tích, xử lý, và hiểu ngôn ngữ con người. Công nghệ này đã và đang mang lại những ứng dụng tương hỗ thiết thực trong những hoạt động giải trí vận hành doanh nghiệp cũng như nâng cao thưởng thức người mua .Một trong những mong ước mãnh liệt, Open từ rất sớm của những nhà khoa học máy tính ( computer science ) nói chung và trí tuệ nhân tạo ( artificial intelligence ) nói riêng là thiết kế xây dựng thành công xuất sắc những mạng lưới hệ thống, chương trình máy tính có năng lực tiếp xúc với con người trải qua ngôn ngữ tự nhiên ( natural language ), tức thứ ngôn ngữ con người sử dụng hàng ngày thay vì những ngôn ngữ lập trình ( programming language ) hay ngôn ngữ máy ( computer language ) bậc thấp. Xử lý ngôn ngữ tự nhiên ( natural language processing ), một nhánh nghiên cứu và điều tra của trí tuệ nhân tạo, trong đó tăng trưởng những thuật toán, thiết kế xây dựng những chương trình máy tính có năng lực nghiên cứu và phân tích, xử lý, và hiểu ngôn ngữ của con người, chính là nghành nghề dịch vụ nhằm mục đích hiện thực hóa tiềm năng này. Do đó ngay từ khi trí tuệ nhân tạo mới sinh ra ( năm 1956 ), những nhà nghiên cứu đã đặt xử lý ngôn ngữ tự nhiên là một trong hai trách nhiệm trọng tâm của trí tuệ nhân tạo, bên cạnh việc tăng trưởng những chương trình máy tính có năng lực thắng lợi con người trong những game show trí tuệ đối kháng. Bài viết này sẽ ra mắt về nghành xử lý ngôn ngữ tự nhiên, những bước cơ bản trong xử lý ngôn ngữ tự nhiên, 1 số ít ứng dụng của xử lý ngôn ngữ tự nhiên, và phương pháp công nghệ tiên tiến này giúp máy tính tiếp xúc với con người .
Xử lý ngôn ngữ tự nhiên là một nhánh của Trí tuệ nhân tạo, tập trung chuyên sâu vào việc nghiên cứu và điều tra sự tương tác giữa máy tính và ngôn ngữ tự nhiên của con người, dưới dạng lời nói ( speech ) hoặc văn bản ( text ). Mục tiêu của nghành nghề dịch vụ này là giúp máy tính hiểu và triển khai hiệu suất cao những trách nhiệm tương quan đến ngôn ngữ của con người như : tương tác giữa người và máy, cải tổ hiệu suất cao tiếp xúc giữa con người với con người, hoặc đơn thuần là nâng cao hiệu suất cao xử lý văn bản và lời nói .
Xử lý ngôn ngữ tự nhiên ra đời từ những năm 40 của thế kỷ 20, trải qua các giai đoạn phát triển với nhiều phương pháp và mô hình xử lý khác nhau. Có thể kể tới các phương pháp sử dụng ô-tô-mát và mô hình xác suất (những năm 50), các phương pháp dựa trên ký hiệu, các phương pháp ngẫu nhiên (những năm 70), các phương pháp sử dụng học máy truyền thống (những năm đầu thế kỷ 21), và đặc biệt là sự bùng nổ của học sâu trong thập kỷ vừa qua.
Xử lý ngôn ngữ tự nhiên hoàn toàn có thể được chia ra thành hai nhánh lớn, không trọn vẹn độc lập, gồm có xử lý lời nói ( speech processing ) và xử lý văn bản ( text processing ). Xử lý lời nói tập trung chuyên sâu nghiên cứu và điều tra, tăng trưởng những thuật toán, chương trình máy tính xử lý ngôn ngữ của con người ở dạng lời nói ( tài liệu âm thanh ). Các ứng dụng quan trọng của xử lý lời nói gồm có nhận dạng lời nói và tổng hợp lời nói. Nếu như nhận dạng tiếng nói là chuyển ngôn ngữ từ dạng lời nói sang dạng văn bản thì ngược lại, tổng hợp lời nói chuyển ngôn ngữ từ dạng văn bản thành lời nói. Xử lý văn bản tập trung chuyên sâu vào nghiên cứu và phân tích tài liệu văn bản. Các ứng dụng quan trọng của xử lý văn bản gồm có tìm kiếm và truy xuất thông tin, dịch máy, tóm tắt văn bản tự động hóa, hay kiểm lỗi chính tả tự động hóa. Xử lý văn bản đôi lúc được chia tiếp thành hai nhánh nhỏ hơn gồm có hiểu văn bản và sinh văn bản. Nếu như hiểu tương quan tới những bài toán nghiên cứu và phân tích văn bản thì sinh tương quan tới trách nhiệm tạo ra văn bản mới như trong những ứng dụng về dịch máy hoặc tóm tắt văn bản tự động hóa .
Xử lý văn bản gồm có 4 bước chính sau :
- Phân tích hình vị: là sự nhận biết, phân tích, và miêu tả cấu trúc của hình vị trong một ngôn ngữ cho trước và các đơn vị ngôn ngữ khác, như từ gốc, biên từ, phụ tố, từ loại, v.v. Trong xử lý tiếng Việt, hai bài toán điển hình trong phần này là tách từ (word segmentation) và gán nhãn từ loại (part-of-speech tagging).
- Phân tích cú pháp: là quy trình phân tích một chuỗi các biểu tượng, ở dạng ngôn ngữ tự nhiên hoặc ngôn ngữ máy tính, tuân theo văn phạm hình thức. Văn phạm hình thức thường dùng trong phân tích cú pháp của ngôn ngữ tự nhiên bao gồm Văn phạm phi ngữ cảnh (Context-free grammar – CFG), Văn phạm danh mục kết nối (Combinatory categorial grammar – CCG), và Văn phạm phụ thuộc (Dependency grammar – DG). Đầu vào của quá trình phân tích là một câu gồm một chuỗi từ và nhãn từ loại của chúng, và đầu ra là một cây phân tích thể hiện cấu trúc cú pháp của câu đó.
- Phân tích ngữ nghĩa: là quá trình liên hệ cấu trúc ngữ nghĩa, từ cấp độ cụm từ, mệnh đề, câu và đoạn đến cấp độ toàn bài viết, với ý nghĩa độc lập của chúng. Nói cách khác, việc này nhằm tìm ra ngữ nghĩa của đầu vào ngôn từ. Phân tích ngữ nghĩa bao gồm hai mức độ: Ngữ nghĩa từ vựng biểu hiện các ý nghĩa của những từ thành phần, và phân biệt nghĩa của từ; Ngữ nghĩa thành phần liên quan đến cách thức các từ liên kết để hình thành những nghĩa rộng hơn.
- Phân tích diễn ngôn: là phân tích văn bản có xét tới mối quan hệ giữa ngôn ngữ và ngữ cảnh sử dụng (context-of-use). Phân tích diễn ngôn, do đó, được thực hiện ở mức độ đoạn văn hoặc toàn bộ văn bản thay vì chỉ phân tích riêng ở mức câu.
Điều gì khiến NLP là một lĩnh vực khó?
Có nhiều nguyên do khiến xử lý ngôn ngữ tự nhiên là một trách nhiệm khó như tập từ vựng rộng lớp và được update liên tục, cấu trúc ngữ pháp linh động và đôi lúc khá lỏng lẻo, ngôn ngữ nhiều lúc biểu lộ xúc cảm, ẩn ý của người viết. Tuy nhiên có hai nguyên do cơ bản nhất là tính nhập nhằng của ngôn ngữ ( ambiguity ) và sự thiết yếu của tri thức nền ( background knowledge ). Tính nhập nhằng ta sẽ trao đổi ở phần sau, trước hết nói về tri thức nền .
Một đứa trẻ, từ khi sinh ra cho tới khi tập nói, tập đọc trải qua một quá trình dài tăng trưởng. Trong quy trình tiến độ này đứa trẻ không ngừng tiếp xúc với quốc tế bên ngoài, có những thưởng thức và tiếp thu kỹ năng và kiến thức từ quốc tế xung quanh. Những tri thức cơ bản từ từ được hình thành như lửa thì nóng, nước đá thì lạnh, đi đường đèn đỏ thì dừng, đèn xanh thì đi, nhưng không có đèn tím. Những tri thức này giúp ích rất nhiều cho con người trong việc hiểu ngôn ngữ. Việc đưa những tri thức nền này vào máy tính là thử thách lớn, đến nay vẫn chưa có giải pháp tốt .
Tiếp đến, về tính nhập nhằng của ngôn ngữ, nhập nhằng là hiện tượng kỳ lạ xảy ra khi ngôn ngữ hoàn toàn có thể được hiểu theo nhiều cách khác nhau, tùy thuộc vào ngữ cảnh mà nó Open. Trong xử lý ngôn ngữ tự nhiên, nhập nhằng hoàn toàn có thể Open ở nhiều Lever, từ vựng, ngữ pháp, ngữ nghĩa, dẫn tới khó khăn vất vả trong việc xử lý trên máy tính. Xét những ví dụ sau :
Ví dụ 1 :
They book that hotel. (S1)
They read that book. (S2)
Đầu tiên, từ book là nhập nhằng về mặt từ loại. Book hoàn toàn có thể là một động từ ( trong câu S1 ) hoặc một danh từ ( trong câu S2 ) tùy thuộc vào ngữ cảnh Open của nó. Hiện tượng này gây khó khăn vất vả cho bài toán gán nhãn từ loại, một bước trong nghiên cứu và phân tích cú pháp. Không chỉ vậy, book cũng nhập nhằng về mặt ngữ nghĩa. Book hoàn toàn có thể là một hành vi đặt hàng thứ gì đó ( trong câu S1 ) hoặc hoàn toàn có thể là một văn bản viết được xuất bản dưới dạng in ấn hay điện tử ( trong câu S2 ). Hiện tượng này gây khó khăn vất vả cho bài toán xác định nghĩa của từ, là một bước trong nghiên cứu và phân tích ngữ nghĩa .
Ví dụ 2:
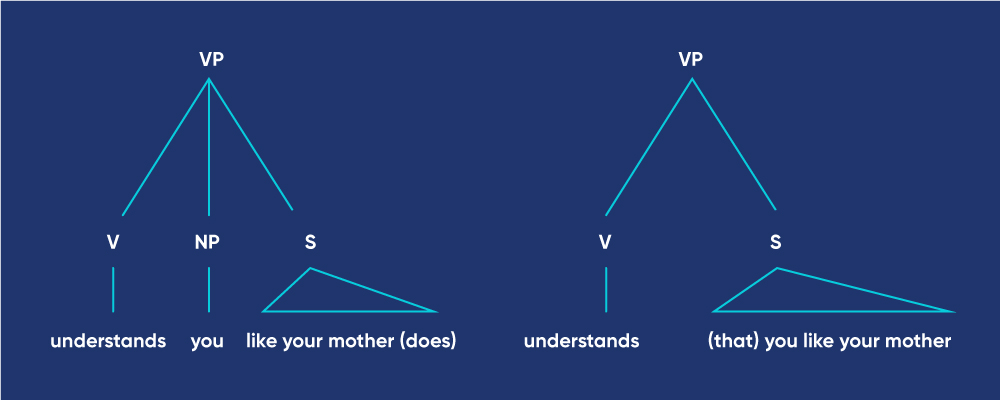
Ở góc nhìn ngữ pháp, câu này hoàn toàn có thể được lý giải theo hai cây cú pháp như trên Hình 1. Những cấu trúc khác nhau dẫn đến những cách hiểu khác nhau : “ a computer understands you like your mother does ” hoặc “ a computer understands that you like your mother ”. Hiện tượng này gây khó khăn vất vả cho cả hai bài toán là nghiên cứu và phân tích cú pháp và nghiên cứu và phân tích ngữ nghĩa .
Bài đọc nhiều nhất
Phát triển du lịch thông minh nhờ ứng dụng nền tảng công nghệ
Artificial Intelligent 08/01/2023
Một số ứng dụng của NLP
NLP ngày càng được ứng dụng nhiều. Một số ứng dụng hoàn toàn có thể kể đến như :
- Nhận dạng tiếng nói (Automatic Speech Recognition – ASR, hoặc Speech To Text – STT) chuyển đổi ngôn ngữ từ dạng tiếng nói sang dạng văn bản, thường được ứng dụng trong các chương trình điều khiển qua giọng nói.
- Tổng hợp tiếng nói (Speech synthesis hoặc Text to Speech – TTS) chuyển đổi ngôn ngữ từ dạng văn bản sang tiếng nói, thường được dùng trong đọc văn bản tự động.
- Truy xuất thông tin (Information Retrieval – IR) có nhiệm vụ tìm các tài liệu dưới dạng không có cấu trúc (thường là văn bản) đáp ứng nhu cầu về thông tin từ những nguồn tổng hợp lớn. Những hệ thống truy xuất thông tin phổ biến nhất bao gồm các công cụ tìm kiếm như Google, Yahoo, hoặc Bing search. Những công cụ này cho phép tiếp nhận một câu truy vấn dưới dạng ngôn ngữ tự nhiên làm đầu vào và cho ra một danh sách các tài liệu được sắp xếp theo mức độ phù hợp.
- Trích chọn thông tin (Information Extraction – IE) nhận diện một số loại thực thể được xác định trước, mối quan hệ giữa các thực thể và các sự kiện trong văn bản ngôn ngữ tự nhiên. Khác với truy xuất thông tin trả về một danh sách các văn bản hợp lệ thì trích chọn thông tin trả về chính xác thông tin mà người dùng cần. Những thông tin này có thể là về con người, địa điểm, tổ chức, ngày tháng, hoặc thậm chí tên công ty, mẫu sản phẩm hay giá cả.
- Trả lời câu hỏi (Question Answering – QA) có khả năng tự động trả lời câu hỏi của con người ở dạng ngôn ngữ tự nhiên bằng cách truy xuất thông tin từ một tập hợp tài liệu. Một hệ thống QA đặc trưng thường bao gồm ba mô đun: Mô đun xử lý truy vấn (Query Processing Module) – tiến hành phân loại câu hỏi và mở rộng truy vấn; Mô đun xử lý tài liệu (Document Processing Module) – tiến hành truy xuất thông tin để tìm ra tài liệu thích hợp; và Mô hình xử lý câu trả lời (Answer Processing Module) – trích chọn câu trả lời từ tài liệu đã được truy xuất.
- Tóm tắt văn bản tự động (Automatic Text Summarization) là bài toán thu gọn văn bản đầu vào để cho ra một bản tóm tắt ngắn gọn với những nội dung quan trọng nhất của văn bản gốc. Có hai phương pháp chính trong tóm tắt, là phương pháp trích xuất (extractive) và phương pháp tóm lược ý (abstractive). Những bản tóm tắt trích xuất được hình thành bằng cách ghép một số câu được lấy y nguyên từ văn bản cần thu gọn. Những bản tóm lược ý thường truyền đạt những thông tin chính của đầu vào và có thể sử dụng lại những cụm từ hay mệnh đề trong đó, nhưng nhìn chung được thể hiện ở ngôn ngữ của người tóm tắt.
- Chatbot là việc chương trình máy tính có khả năng trò chuyện (chat), hỏi đáp với con người qua hình thức hội thoại dưới dạng văn bản (text). Chatbot thường được sử dụng trong ứng dụng hỗ trợ khách hàng, giúp người dùng tìm kiếm thông tin sản phẩm, hoặc giải đáp thắc mắc.
- Dịch máy (Machine Translation – MT) là việc sử dụng máy tính để tự động hóa một phần hoặc toàn bộ quá trình dịch từ ngôn ngữ này sang ngôn ngữ khác. Các phương pháp dịch máy phổ biến bao gồm dịch máy dựa trên ví dụ (example-based machine translation – EBMT), dịch máy dựa trên luật (rule-based machine translation – RBMT), dịch máy thống kê (statistical machine translation – SMT), và dịch máy sử dụng mạng nơ-ron (neural machine translation).
- Kiểm lỗi chính tả tự động là việc sử dụng máy tính để tự động phát hiện các lỗi chính tả trong văn bản (lỗi từ vựng, lỗi ngữ pháp, lỗi ngữ nghĩa) và đưa ra gợi ý cách chỉnh sửa lỗi.
Giao tiếp giữa người và máy dựa trên NLP
Ngày nay, nhiều mạng lưới hệ thống / chương trình máy tính có năng lực tiếp xúc với con người trải qua ngôn ngữ tự nhiên, hoặc dưới dạng văn bản, hoặc dưới dạng lời nói. Các ứng dụng tiêu biểu vượt trội tiếp xúc dưới dạng văn bản hoàn toàn có thể kể đến như tìm kiếm thông tin, chatbot, dịch máy. Các ứng dụng tiếp xúc qua lời nói như trợ lý ảo, tìm kiếm bằng giọng nói ( điện thoại cảm ứng, tivi ), và điều khiển và tinh chỉnh qua giọng nói ( điện thoại cảm ứng, những thiết bị mái ấm gia đình ) .
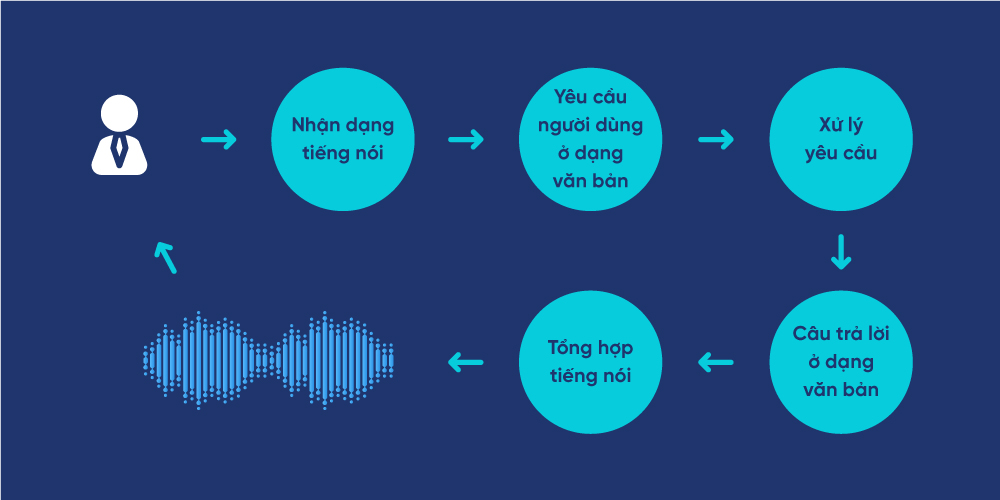
Hình 2 diễn đạt kiến trúc tiêu biểu vượt trội của một chương trình máy tính tiếp xúc với con người qua lời nói. Chương trình sẽ gồm có những bước cơ bản sau :
- Nhận dạng tiếng nói: ở bước này, máy tính sẽ nhận dạng yêu cầu của người dùng ở dạng tiếng nói và chuyển yêu cầu này về dạng văn bản.
- Xử lý yêu cầu: máy tính sẽ phân tích yêu cầu ở dạng văn bản, xử lý, đưa ra câu trả lời sử dụng các kỹ thuật trong xử lý văn bản.
- Tổng hợp tiếng nói: ở bước này, câu trả lời sẽ được chuyển từ dạng văn bản sang tiếng nói và gửi tới người dùng.
Công nghệ xử lý ngôn ngữ tự nhiên ngày càng có nhiều ứng dụng tốt, dần phổ biến, và gần gũi với cuộc sống hàng ngày. Với sự tiến bộ không ngừng về mặt kỹ thuật, tốc độ xử lý, độ chính xác được cải thiện, xử lý ngôn ngữ tự nhiên đã từng bước trở thành công nghệ giúp máy tính hiểu và giao tiếp với con người thông qua ngôn ngữ của chính chúng ta.





